
Dominate Your Data: 28 Best DataOps Tools You Can’t Miss In 2024

The CTO is reader-supported. We may earn a commission when you click through links on our site—read our affiliate disclosure to learn more about how we aim to stay transparent.
12 Best DataOps Tools
After a thorough evaluation, I've curated the 12 best DataOps tools, each handpicked to address your unique data challenges. Let's dive in!
- Badook - Best for comprehensive data testing and validation
- StreamSets - Best for managing data in motion with agility
- HighByte - Best for industrial data integration and orchestration
- RightData - Best for data quality validation and reconciliation
- DataKitchen - Best for creating and governing data pipelines
- Databricks - Best for large-scale data engineering and analytics
- Apache Nifi - Best for real-time data ingestion and streaming
- Apache Hive - Best for querying and managing large datasets
- Elastic - Best for real-time search and data analytics
- Azure Data Factory - Best for hybrid data integration at a global scale
- Alteryx - Best for advanced analytics and business intelligence
- IBM - Best for robust enterprise-grade data operations
DataOps tools represent a significant leap in methodology for managing and integrating data assets in today's complex data environments. As a seasoned data professional myself, I have firsthand experience of how APIs, AWS, apps, and the broader data stack can be skillfully orchestrated to unlock immense business value.
From my perspective, a robust DataOps tool, like Datafold, can effectively streamline the data management process, fostering greater observability across your data assets and helping you monitor critical metrics. Trust me when I say, navigating the complexity of modern data landscapes becomes much easier when you've got a reliable DataOps tool in your arsenal. Take a look at the options I've laid out – you'll thank me later.
What Is a DataOp Tool?
DataOps tools are innovative platforms designed to enhance data management, providing businesses the ability to refine data processing and analytics. Often employed by data scientists, analysts, and data-driven organizations, these tools offer improved collaboration, real-time data access, and efficient data pipeline management, ensuring a smooth transition from raw data to actionable insights.
The power of these tools lies in their ability to address common pain points in software development and data management. They not only enhance operational efficiency but also pave the way for more strategic use of data. By integrating various data sources, these tools minimize data silos and enable a holistic view of data, facilitating improved decision-making.
With the help of DataOps tools, businesses can accelerate decision-making processes, drive innovation, and streamline operational efficiency. They serve as a significant asset in creating a culture of agility, transparency, and responsiveness in managing a company's most valuable resource - data.
Overviews of the 12 Best DataOps Tools
1. Badook - Best for comprehensive data testing and validation
Badook is a data testing platform dedicated to ensuring data quality at every stage of your data pipelines. It allows organizations to easily test, monitor, and validate data, reflecting why it's best for comprehensive data testing and validation.
Why I Picked Badook:
In my evaluation, I chose Badook for its innovative approach to data quality assurance. By providing comprehensive testing and validation, it ensures that decision-makers and data analysts work with the most accurate data. It is indeed best for comprehensive data testing and validation, offering a solid framework for validating data consistency, completeness, and conformity.
Standout Features & Integrations:
Badook shines with its unique features like data health scoring, real-time data testing, and automated data validation. The ability to generate custom testing rules adds flexibility to the platform. Its integrations include but are not limited to, widely-used databases like MySQL, Oracle, and MongoDB, as well as data warehousing solutions such as Snowflake and Redshift.
Pricing:
Pricing starts from $500/user/month (billed annually), providing access to all core features.
Pros:
- Robust data testing capabilities
- Offers data health score
- Broad range of integrations
Cons:
- Higher starting price than some competitors
- Steeper learning curve for beginners
- Billed annually, not monthly
2. StreamSets - Best for managing data in motion with agility
StreamSets is a dynamic DataOps platform focused on handling data in motion. With its suite of tools designed for agility and efficiency, it rightfully earns its position as best for managing data in motion with agility.
Why I Picked StreamSets:
I chose StreamSets due to its superior capacity to manage streaming data, a feature that makes it stand out from its peers. The platform brings a degree of agility to data movement that I found unique during my evaluation. This agility allows for efficient handling of real-time data, justifying why it's best for managing data in motion.
Standout Features & Integrations:
StreamSets comes packed with features like data drift handling, smart pipeline execution, and performance optimization. These capabilities ensure efficient data flow without compromise. In terms of integrations, it is compatible with several popular systems such as Apache Kafka, Amazon S3, Salesforce, and Google BigQuery, among others.
Pricing:
Pricing starts from $125/user/month (billed annually), and it includes access to all fundamental features.
Pros:
- Exceptional handling of data in motion
- Comprehensive suite of features
- Broad range of integrations
Cons:
- Might be expensive for small businesses
- Requires a certain level of technical know-how
- Billed annually, which may deter some potential users
3. HighByte - Best for industrial data integration and orchestration
HighByte is an industrial data ops software designed specifically to address the unique challenges of industrial data. Its specialization in industrial data orchestration supports the notion that it's best for industrial data integration and orchestration.
Why I Picked HighByte:
I selected HighByte because of its keen focus on industrial data, a niche that many other tools do not cover. Its tailored solutions for the industrial sector set it apart from its competitors. This industry-specific orientation allows it to excel in data integration and orchestration for industrial environments, which is why it's best for this particular use case.
Standout Features & Integrations:
HighByte's most noteworthy features include edge-to-cloud data integration, model-based data contextualization, and secure data transmission. It offers integration with common industrial protocols and systems such as OPC UA, MQTT, SQL databases, and more.
Pricing:
Pricing begins from $100/user/month (billed annually). This price covers the basic functionalities and support.
Pros:
- Tailored for industrial data needs
- Model-based data contextualization feature
- Secure data transmission
Cons:
- Might not suit non-industrial use cases
- Requires industrial data expertise
- Higher cost than some alternatives
4. RightData - Best for data quality validation and reconciliation
RightData serves as a self-service, automated data quality validation and reconciliation platform. Its core capabilities of ensuring data integrity position it as the best tool for data quality validation and reconciliation.
Why I Picked RightData:
RightData was my choice due to its laser-focused approach to ensuring data quality, a criterion that often proves critical in decision-making processes. Its unique selling proposition is its automated, end-to-end data validation and reconciliation which, in my opinion, makes it best for these functions.
Standout Features & Integrations:
RightData's features such as data profiling, data quality validation, and reconciliation are truly exceptional. Moreover, it integrates well with popular databases and ETL tools, ensuring a smooth flow of data through various systems.
Pricing:
RightData's pricing begins at $50/user/month (billed annually), which includes basic data quality validation and reconciliation features.
Pros:
- Dedicated tool for data quality validation
- Automated reconciliation feature
- Integrates with popular databases and ETL tools
Cons:
- Less suited for non-validation tasks
- May require initial setup expertise
- No monthly billing option
5. DataKitchen - Best for creating and governing data pipelines
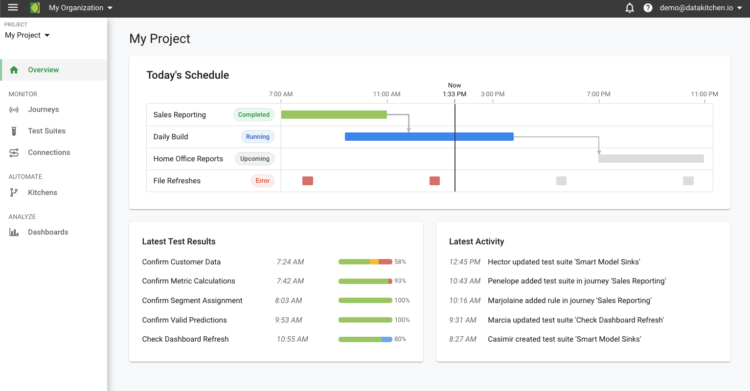
DataKitchen offers an end-to-end DataOps platform, enabling data analytics teams to automate and coordinate data pipelines. Given its proficiency in pipeline management and governance, it stands out as the best tool for creating and overseeing data pipelines.
Why I Picked DataKitchen:
I picked DataKitchen due to its strong emphasis on reducing errors and improving efficiency in data pipeline creation and governance. Its standout feature, the 'DataOps Nervous System,' supports comprehensive data pipeline orchestration, which sets it apart from other tools. This feature has guided my judgment that DataKitchen excels at managing data pipelines.
Standout Features & Integrations:
DataKitchen's 'DataOps Nervous System' provides automation and coordination of all elements of the data pipeline. The platform also integrates with the most popular data science, business intelligence, ETL tools, and databases, enhancing its capacity to handle diverse data systems.
Pricing:
Pricing for DataKitchen starts at $250/user/month (billed annually), which includes access to its core DataOps features.
Pros:
- Robust automation for data pipeline creation
- 'DataOps Nervous System' for governance
- Integrates with the most popular data tools
Cons:
- Higher entry-level price compared to some alternatives
- Might be complex for users unfamiliar with DataOps concepts
- Only offers annual billing
6. Databricks - Best for large-scale data engineering and analytics
Databricks is a unified platform designed to make big data analytics and AI accessible to data teams. Its distinctive architecture allows large-scale data processing, making it suitable for extensive data engineering and analytics tasks.
Why I Picked Databricks:
I chose Databricks because it provides an optimized platform for running Apache Spark, which is a leading tool for working with large-scale data. What separates Databricks from other tools is its collaborative workspace that brings together data engineers, data scientists, and business analysts.
This collaborative environment and its prowess in large-scale data tasks justify why it's best for big data engineering and analytics.
Standout Features & Integrations:
Databricks comes equipped with the Databricks Runtime, which improves upon the open-source Apache Spark for better performance and usability. It also offers MLflow for managing the machine learning lifecycle. It easily integrates with many data storage solutions, including but not limited to Azure Data Lake Storage, Amazon S3, and Hadoop Distributed File System (HDFS).
Pricing:
The pricing for Databricks starts from $99/user/month, covering all foundational features. The pricing varies based on the usage of Databricks Units (DBUs), a processing capability measure.
Pros:
- Streamlines large-scale data processing
- Collaborative workspace for data engineers, scientists, and analysts
- Optimized for Apache Spark with better performance
Cons:
- Pricing can be complex due to dependence on DBUs
- Steeper learning curve for beginners
- Advanced features may require additional costs
7. Apache NiFi - Best for real-time data ingestion and streaming
Apache NiFi is an integrated data logistics platform for automating the movement of data between disparate systems. It provides real-time control that makes it responsive to highly volatile big data streams, making it the ideal choice for real-time data ingestion and streaming.
Why I Picked Apache NiFi:
I picked Apache NiFi for its high-speed data routing and transformation capabilities. Its unique design allows for tracking data in real-time and creating dynamic, responsive data flows. These standout features are the reason I believe Apache NiFi is best for real-time data ingestion and streaming.
Standout Features & Integrations:
Apache NiFi's standout features include a highly configurable web-based UI, data provenance to track data from origin to consumption, and flexible scaling abilities. NiFi integrates well with numerous data systems, including but not limited to, HTTP, AMQP, HDFS, and Database via JDBC.
Pricing:
Since Apache NiFi is an open-source project, it's free to use, but you may incur costs associated with infrastructure, operation, and maintenance.
Pros:
- Provides real-time control of data flows
- Extensive data routing and transformation capabilities
- Open-source and customizable
Cons:
- Requires a technical understanding to operate effectively
- Setup and configuration can be complex
- Lack of direct vendor support due to open-source nature
8. Apache Hive - Best for querying and managing large datasets
Apache Hive is a data warehouse software project that facilitates reading, writing, and managing large datasets in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. It's these features that make Hive excellent for querying and managing large datasets.
Why I Picked Apache Hive:
I chose Apache Hive because of its scalability and its familiar, SQL-like querying language, HiveQL. Its architecture allows the processing of enormous amounts of data, making it a distinctive choice for managing large datasets.
Consequently, I deem Apache Hive best for querying and managing sizeable data stores.
Standout Features & Integrations:
Apache Hive's key features are its capacity for petabyte-scale reads/writes, a SQL-like interface that is easy for data analysts to use, and the flexibility to support various data formats. As part of the Hadoop ecosystem, Hive integrates seamlessly with other tools in the Hadoop family, like HBase, ZooKeeper, and YARN.
Pricing:
As an open-source software, Apache Hive is free to use. However, infrastructure, maintenance, and potential support costs may apply depending on your specific use case.
Pros:
- Scales to handle petabytes of data
- SQL-like language, HiveQL, which is easy for data analysts
- Integrates with the broader Hadoop ecosystem
Cons:
- Lack of speed in real-time querying scenarios
- Could be complex to set up and manage for beginners
- Open-source nature means no direct vendor support
9. Elastic - Best for real-time search and data analytics
Elastic is an open-source search and analytics engine that provides real-time insights from your data. Its core function is to store, search, and analyze vast amounts of data quickly and in near real-time. This makes Elastic exceptionally proficient for real-time search and data analytics tasks.
Why I Picked Elastic:
I chose Elastic due to its high-speed search capabilities and its ability to handle massive datasets effectively. Its powerful search features, coupled with its real-time analytics capabilities, make Elastic stand out from other tools.
Based on these capabilities, I determined Elastic to be the best tool for real-time search and data analytics.
Standout Features & Integrations:
Some of Elastic's most important features include full-text search, distributed search, and real-time analytics. Its real-time, multi-level aggregation functionality helps users explore and analyze their data more intuitively.
It also integrates with numerous data collection and visualization tools, including Logstash for centralized logging and Kibana for data visualization.
Pricing:
Pricing for Elastic starts from $16/user/month for their Gold subscription. This is their lowest-priced paid plan that includes features like anomaly detection and machine learning capabilities.
Pros:
- Provides fast and efficient search results
- Can handle large datasets
- Flexible with data formats
Cons:
- Steeper learning curve compared to some other tools
- Configuring and tuning Elastic for specific use cases can be complex
- While the basic Elastic stack is free, advanced features come with a cost
10. Azure Data Factory - Best for hybrid data integration at a global scale
Azure Data Factory is a cloud-based data integration service provided by Microsoft that enables you to create data-driven workflows for orchestrating and automating data movement and data transformation. Its ability to integrate both on-premises and cloud data makes it a top choice for organizations requiring hybrid data integration on a global scale.
Why I Picked Azure Data Factory:
In evaluating various tools, I selected Azure Data Factory for its robustness and capability to handle hybrid data integration on a global scale. It excels in integrating and transforming large volumes of raw data, which comes from various heterogeneous sources, into actionable insights.
Given its extensive capabilities and global reach, I found Azure Data Factory to be the best fit for hybrid data integration at a global scale.
Standout Features & Integrations:
Azure Data Factory features include data-driven workflows, data movement and transformation, and a hybrid data integration service. It also offers extensive data source connectivity both in the cloud and on-premises, such as SQL Server, Oracle Database, and Amazon Redshift, to name a few.
In terms of integration, Azure Data Factory smoothly integrates with other Azure services like Azure Databricks, Azure Synapse Analytics, and Azure Machine Learning.
Pricing:
Pricing for Azure Data Factory starts from approximately $1/user/hour for data movement activities. Microsoft bills are based on the number of read/write operations, data movement activities, and orchestration activities, making pricing complex and dependent on usage.
Pros:
- Provides seamless integration of on-premises and cloud data
- Scalability and flexibility in handling large volumes of data
- High availability and reliability
Cons:
- Complex pricing model
- Requires Azure expertise for optimal usage
- Limited built-in transformation capabilities
11. Alteryx - Best for advanced analytics and business intelligence
Alteryx is a self-service analytics platform that allows users to combine data, perform advanced analytics, and understand their data with business intelligence. Its unique blend of data management, analytics, and BI capabilities makes it an exceptional choice for organizations seeking in-depth insights from their data.
Why I Picked Alteryx:
In my selection process, Alteryx stood out due to its superior analytics and business intelligence offerings. This tool offers a user-friendly interface for complex data tasks, which is a distinction not commonly found in other tools in its category. My judgment is that Alteryx is "best for" advanced analytics and business intelligence due to its seamless handling of complex data blending, predictive analytics, and spatial analytics tasks.
Standout Features & Integrations:
Alteryx offers features such as data blending, advanced analytics, data cataloging, and automated machine learning, all of which enhance its data management capabilities. It also integrates effectively with a range of other software, such as Microsoft Excel, SQL Server, Oracle, and a host of cloud data platforms, which further enhances its data handling and analytic capabilities.
Pricing:
Pricing for Alteryx starts from $5,195/user/year (equivalent to about $433/user/month), billed annually. The quoted price is for Alteryx Designer, the starting level for individual analysts.
Pros:
- Offers a wide range of data preparation and blending options
- Strong predictive analytics and machine learning capabilities
- User-friendly interface, suitable for non-technical users
Cons:
- High starting price may be a barrier for small businesses
- Limited visualization options compared to dedicated BI tools
- Steeper learning curve for advanced features
12. IBM - Best for robust enterprise-grade data operations
IBM provides a vast array of data management and analytics tools as part of its comprehensive enterprise solution offerings. From databases to machine learning platforms, IBM's solutions equip businesses to execute large-scale, complex data operations effectively, aligning with the statement that it's "best for robust enterprise-grade data operations."
Why I Picked IBM:
In selecting IBM for this list, it was the breadth and robustness of their data solution offerings that caught my attention. IBM's reputation for providing reliable and high-performing enterprise-grade solutions was another deciding factor.
The depth of its tools and their proven performance in managing complex, large-scale data operations makes IBM the "best for" robust enterprise-grade data operations.
Standout Features & Integrations:
IBM's offerings stand out for their comprehensive nature, which includes tools for data integration, data quality, master data management, and data governance. Their Watson platform offers artificial intelligence capabilities for data analysis.
IBM's solutions integrate effectively with a multitude of third-party tools and data sources, enabling seamless data operations in complex enterprise environments.
Pricing:
Pricing for IBM's data management and analytics solutions is upon request. Given the enterprise-grade nature of their offerings, a detailed consultation with IBM's team would be necessary to determine the most suitable solutions and the corresponding pricing.
Pros:
- Comprehensive suite of enterprise-grade data tools
- Offers robust security and governance features
- Highly customizable to meet the unique needs of large organizations
Cons:
- Can be complex and require specialized skills to utilize fully
- Cost may be prohibitive for small and medium-sized businesses
- Customization and setup can be time-consuming
Other DataOps Tools
Below is a list of additional DataOps tools that I shortlisted, but did not make it to the top 12. Definitely worth checking them out.
- Perfect - Good for building, scheduling, and monitoring data workflows
- Composable - Good for data discovery, integration, and analytics platform
- Airflow - Good for orchestrating complex computational workflows and data processing pipelines
- Snowflake - Good for a fully-managed cloud data platform
- dbt - Good for data modeling and transformation within analytics teams
- Kafka - Good for real-time data streaming and processing needs
- Cloudera - Good for enterprise data cloud needs
- Kubernetes - Good for automated deployment, scaling, and management of containerized applications
- Beam - Good for unified batch and real-time data processing
- Talend - Good for integrated data management and data integration needs
- Trifecta - Good for data preparation and data wrangling needs
- Hadoop - Good for distributed processing of large data sets across clusters of computers
- Druid - Good for real-time analytics on large volumes of data
- Jupyter - Good for interactive data science and scientific computing
- Qubole - Good for cloud-native big data activation platform
- Atlan - Good for collaborative workspace for data-driven teams
Selection Criteria
In my quest to find the best data processing and analytics tools, I embarked on a testing journey where I tried out more than 30 tools. From this extensive pool, I narrowed down my favorites, which excelled in certain key aspects that are essential in this field. The following factors were paramount in my decision-making process:
Core Functionality
- Capability to process large volumes of data
- Ability to handle structured and unstructured data
- Efficient data transformation and modeling capabilities
- Real-time data streaming and analytics
Key Features
- Scalability: How well the tool can handle increasing data volume and complexity without a corresponding increase in resources
- Security: Built-in security features to ensure data protection and compliance with data privacy regulations
- Cloud-Native: Being cloud-native offers flexibility, scalability, and lower infrastructure costs
- Data Integration: The tool's ability to connect and integrate with various data sources
Usability
- Intuitive Interface: For data tools, it's important that they offer a user-friendly interface that abstracts complex functionalities, so even users without extensive technical knowledge can navigate effectively
- Easy onboarding: Comprehensive documentation, tutorials, and responsive customer support are necessary for quick and easy onboarding of new users
- Collaborative Features: Data processing and analytics is often a team effort. Thus, the presence of features that enhance collaboration, such as shared dashboards, is valuable
- Customizability: The ability to customize the tool according to specific business requirements and workflows enhances usability.
People Also Ask (FAQs)
What are the benefits of using DataOps tools?
DataOps tools offer numerous advantages. Here are five key benefits:
- Efficiency: They automate repetitive tasks in the data pipeline, significantly reducing the time and effort involved in data handling.
- Data Quality: By providing functionalities such as data cleansing, validation, and profiling, these tools help maintain high data quality.
- Collaboration: They foster collaboration between various teams such as data scientists, engineers, and business users by providing a common platform for data access and analytics.
- Scalability: These tools are built to handle growing data volumes and complexity, enabling businesses to scale their data operations without substantial infrastructural investments.
- Security and Compliance: DataOps tools often include security features and ensure data privacy regulation compliance, essential in the data-driven business world.
How much do these tools typically cost?
The cost of DataOps tools can vary significantly based on the specific tool, its features, and the pricing model it adopts. Some tools are open-source and free to use, while others might charge based on the volume of data processed, the number of users, or a combination of both.
What are the typical pricing models for DataOps tools?
There are several common pricing models:
- User-Based Pricing: Charges are based on the number of users.
- Data-Based Pricing: Fees depend on the volume of data processed or stored.
- Feature-Based Pricing: Costs depend on the features and capabilities you choose to access.
What is the typical price range for DataOps tools?
Prices can range from free open-source tools to several thousands of dollars per month for enterprise-grade solutions with advanced features. Some tools offer a free tier or trial period, while others start from around $20/user/month and can go up to $1000/user/month for high-end options.
What are the cheapest and most expensive software options?
On the lower end of the spectrum, tools like Apache Airflow and Apache Hadoop are open-source and free to use, though you might incur costs for infrastructure and management. On the higher end, enterprise-grade solutions like Talend and Snowflake can run into several thousand dollars per month, depending on the scale of your operations and the features you require.
Are there any free tool options?
Yes, there are free DataOps tools available. Examples include Apache Airflow and Apache Hadoop. These are open-source platforms that offer robust data operations capabilities. However, while the software is free, deploying and maintaining these systems might require substantial resources and technical expertise.
More DataOps Tool Reviews
Summary
To wrap up, choosing the right DataOps tools can greatly streamline your data operations and significantly enhance your team's productivity. As you consider your options, it's crucial to bear in mind the specific needs of your organization, the complexity of your data processes, and the resources at your disposal.
Key Takeaways
- Align Functionality with Needs: Different DataOps tools come with different capabilities. Ensure that the tool you select aligns with your specific requirements. This could be anything from real-time data analytics to robust enterprise-grade data operations. The best tool is the one that fills the gaps in your data processes seamlessly.
- Consider the Learning Curve: Usability is a critical factor when choosing a DataOps tool. The ease of onboarding, the intuitiveness of the interface, and the availability of customer support can significantly impact the tool's adoption within your team and its overall effectiveness.
- Evaluate the Pricing Structure: It's essential to understand the pricing structure of each tool. Some may have a flat fee, while others might charge per user or based on the data processed. Find a balance between the capabilities you need and the amount you're willing to invest. Also, consider the long-term value and scalability of the tool as your data operations grow.
Remember, the goal is not to find the tool with the most features, but rather the tool that best fits your organization's needs.
What Do You Think?
I hope this guide has been helpful in narrowing down your options for the best DataOps tools. However, the landscape of data operations is vast and continuously evolving, so there may be other noteworthy tools out there that I haven't covered in this list.
If you're using a tool that you believe should be included, please feel free to share it. Your insights and experiences can provide great value to other readers. Thank you for your contributions to this ongoing conversation about the best tools for optimizing data operations.